What do we (not) know about Domain-Driven Design?
In 2004, Evans wrote the beautiful “Domain-driven design: tackling complexity in the heart of software” book. In a nutshell, Evans shows that the true complexity of the system (its heart) often relies on its domain model. The book then presents several patterns to support the modelling of domain models. I myself consider this book compulsory for Software Engineers.
Influenced by Christopher Alexander’s pattern style, the book contains a total of 43 patterns divided into four parts. The book rapidly drew practitioners’ attention: Different authors started to write their own books on DDD, Stack Overflow contains more than 4,000 questions and 7,000 answers related to the topic (on January 27th, 2017), developers exchanged 24,000 e-mails in the official mailing list that is hosted at Yahoo Groups!, and there exist even dedicated conferences for the topic, such as DDDEurope.
The high number of questions and discussions make sense. After all, if you ever tried to implement DDD, you probably faced challenges, ranging from “how to model X” to “how to implement this in practice when using Hibernate”.
 Patterns in the DDD book
Patterns in the DDD book
So, why not investigate what developers are actually asking about DDD in websites like Stack Overflow and Yahoo! Groups? What are the most discussed DDD patterns? What kind of questions do developers ask? How often does a discussion become technical (i.e. contains source code)? What are the most common cited references in these discussions? How do the topics correlate to each other?
In Stack Overflow (SO), we extracted all the questions under the #ddd tag. The sample contains 4,076 questions, the first being posted on August 24th, 2008, and the last one being posted on January 27th, 2017. These questions together received 7,799 answers. The number of the questions vary from 381 questions (in 2009) to 593 (in 2011). We see an increase in number of questions after 2010 which remained similar until 2015. In 2016, we observe a small drop. Similarly, the number of answers vary from 720 (in 2016) to 1,176 (in 2011). Each question receives a median of 2 answers. These posts were made by 2,176 different users. The median number of posts made by a user is 1 (max=26).
We scraped Yahoo! Groups (YG) page as there is no API to extract the discussions. If the message title didn’t contain “RE:”, we marked it as a question, or as an answer, otherwise. We performed some text cleaning to remove signatures, repeated bodies (email clients often attach the previous e-mail below the new e-mail), and ads that Yahoo! sometimes adds to e-mails. The sample contains 5,091 e-mails and 19,514 answers. The first e-mail was posted on September 6th, 2001. Every e-mail receives a median of 5 answers. E-mails were sent by 1,765 different users. The list had a peak on the number of e-mails and answers in 2009, with 1,689 e-mails and 5,693 answers. The number of e-mails dramatically dropped in 2014 (48), 2015 (33), and 2016 (18).
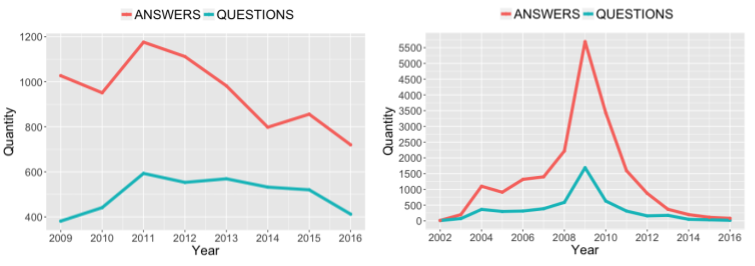 Questions and answers over time in StackOverflow (left) and Yahoo! Groups (right)
Questions and answers over time in StackOverflow (left) and Yahoo! Groups (right)
What are the most discussed Domain-Driven Design patterns?
-
Patterns in Part II are far more popular than other parts of the book. Three of these patterns (Entity, Service, and* Repository) appear in more than 1,000 questions in both Stack Overflow and YG. *Aggregates are also popular in both (1,041 questions in SO and 936 in YG). Entities, in particular, are the most popular one, appearing in 1,841 questions (45% of all questions) and 2,539 answers (32% of all answers) in SO, and in 1,351 questions (27%) and 3,934 (20%) in YG. No other part of the book contains such popular patterns. On the other hand, Part IV is the least popular one, as most patterns contains zero or less than 10 questions. *Bounded Context *is an exception in both datasets, appearing in 231 questions and in 451 answers in SO, and in 196 initial e-mails and 621 answers in YG.
-
There exist questions that do not focus on any pattern. Although, as expected, most questions focus on the patterns defined in the book, some of them do not. In SO, 18% of them do not mention any of them. This number is higher in the YG: 41%.
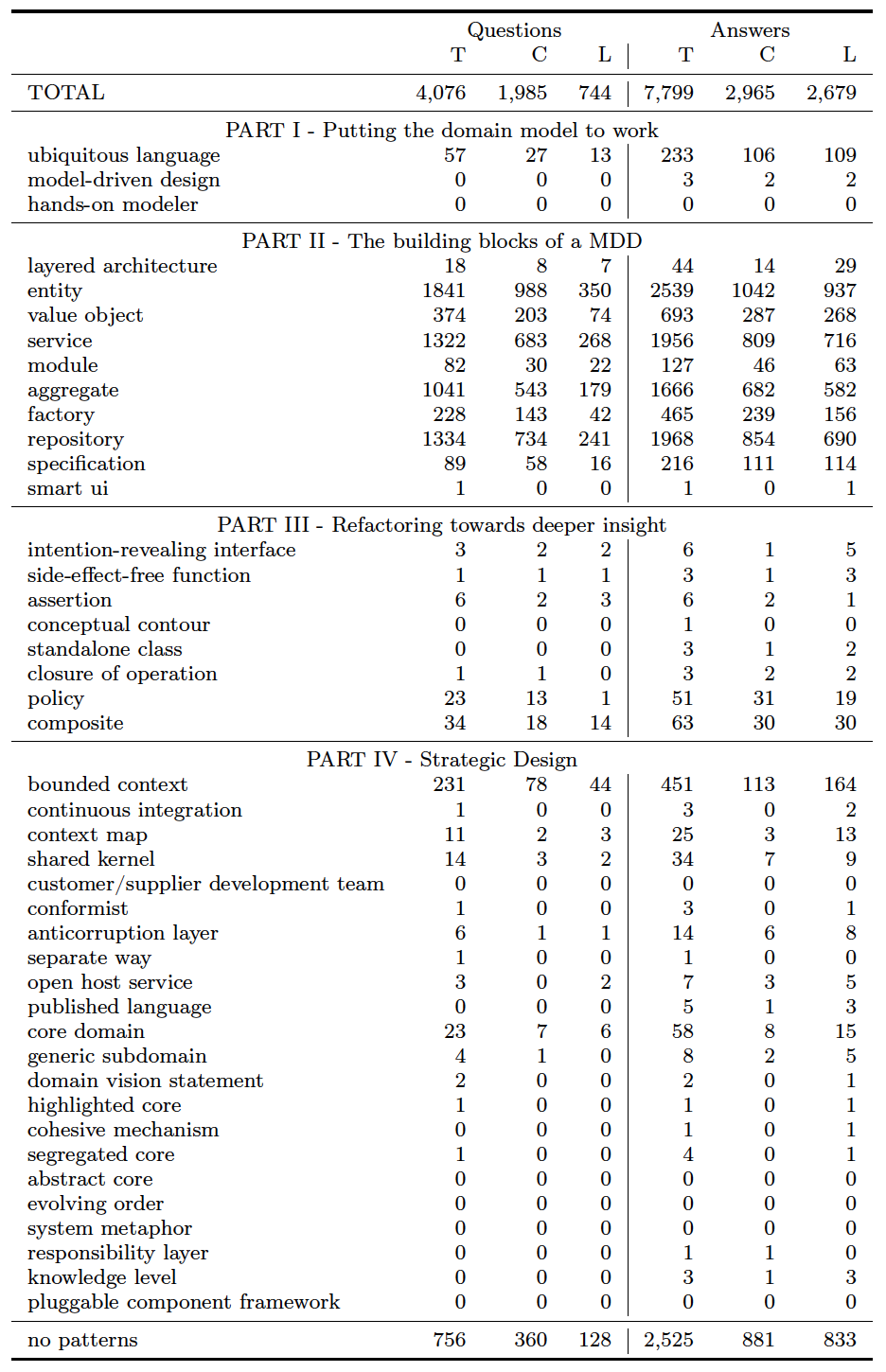 Number of questions and answers mentioning DDD patterns. T=Total of questions/answers, C=Questions/answers with source code, L=Questions/Answers with links.
Number of questions and answers mentioning DDD patterns. T=Total of questions/answers, C=Questions/answers with source code, L=Questions/Answers with links.
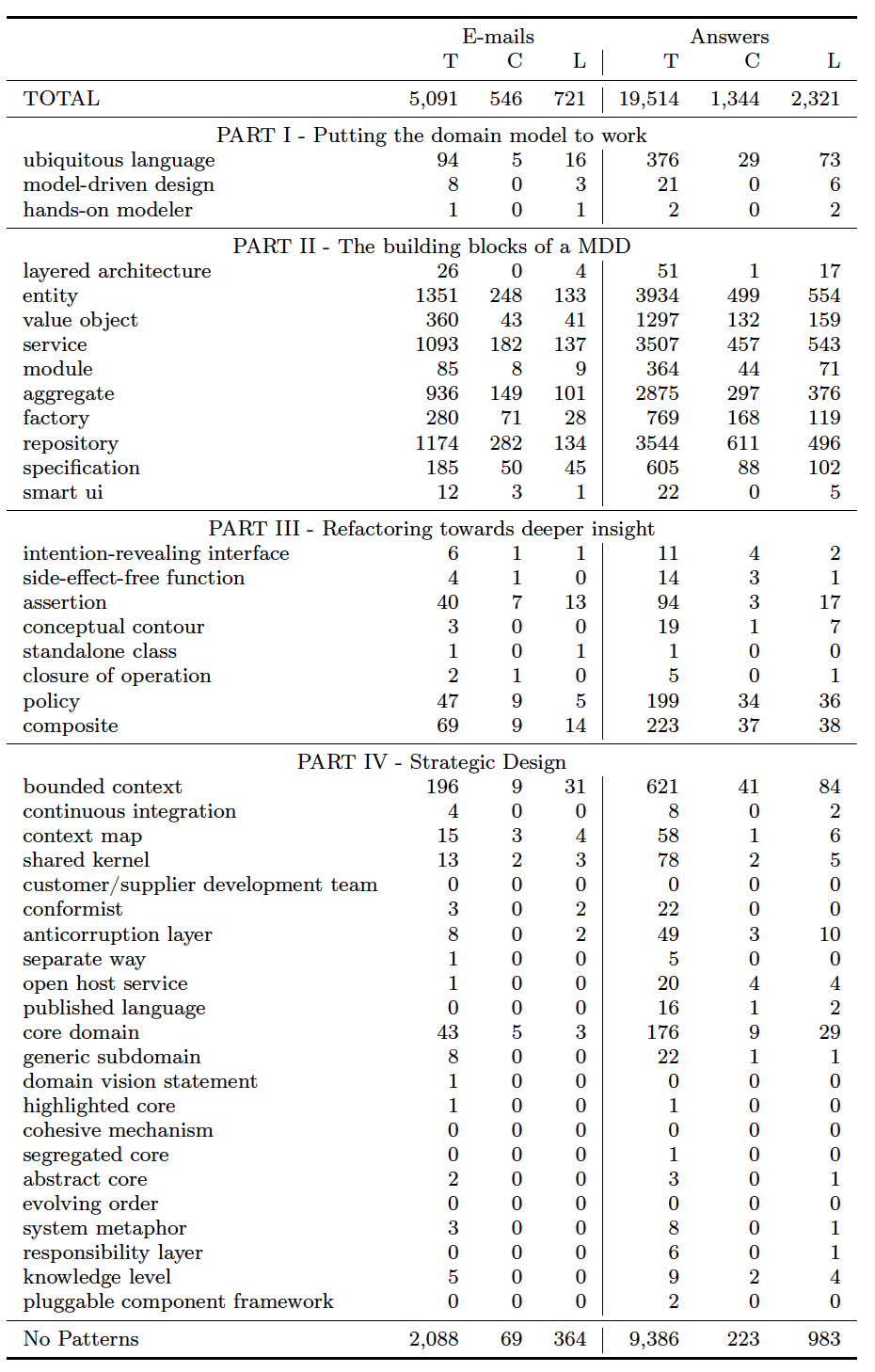 Number of e-mails and answers mentioning DDD patterns in Yahoo! Groups. T=Total of questions/answers, C=Questions/answers with source code, L=Questions/Answers with links.
Number of e-mails and answers mentioning DDD patterns in Yahoo! Groups. T=Total of questions/answers, C=Questions/answers with source code, L=Questions/Answers with links.
What kind of questions do developers ask?
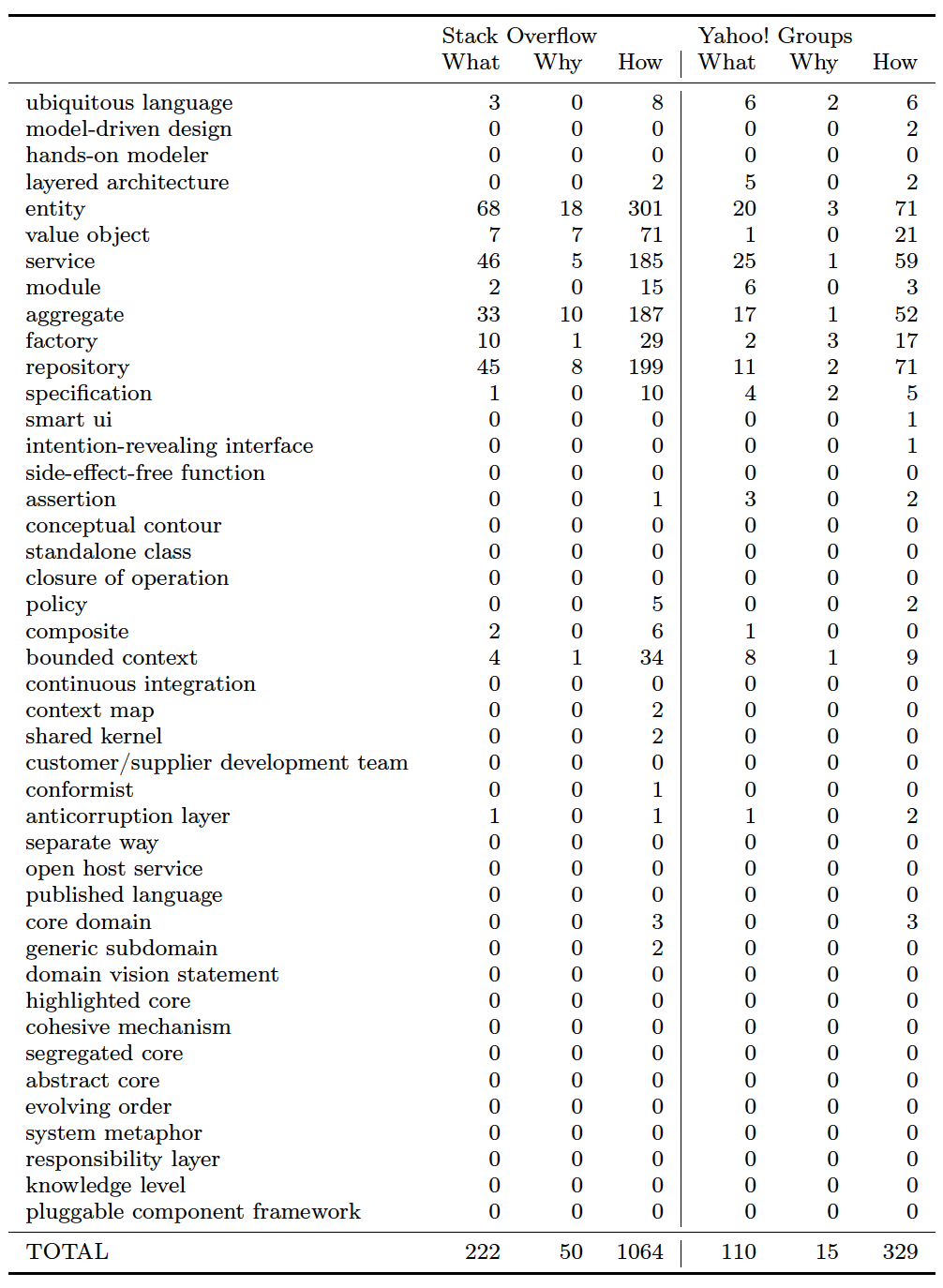
We counted the number of “what”s, “how”s and “why”s that appeared in the title of all posts. Questions in SO seemed to follow this convention better than posts in YG.
-
“How” is the most popular type of question. In SO, we observed 1,064 how questions, 222 what questions, and 50 why questions. In YG, we counted 329 how questions, 110 what questions, and 15 why questions.
-
Entity is by far the one with more “how” questions. Entity received 301 how questions in SO. It is then followed by Repositories *(199), *Aggregates (187) and Services (185). In other parts of the book, Bounded Context (34) is the most popular one, although far from the aforementioned ones.
 Types of questions (what, why, how) in SO and YG
Types of questions (what, why, how) in SO and YG
How often does a discussion become technical (i.e. contains source code)?
-
The number of questions and answers with implementation details is significant. A significant number of questions and answers contain pieces of source code. Patterns in Part II are the ones with more source code. While this is related to the fact that Part II is the most popular one in SO, some patterns contain a high frequency of implementation details in their questions and answers. The Specification pattern, as an example, contains source code in 65% of its questions and in 51% of its answers. Similar numbers happen in many other patterns.
-
Questions and answers in SO are more likely to have source code than e-mails in YG. In SO, we observe 1,985 and 2,091 questions with and without source code, respectively. In YG, these numbers go down to 546 and 4,545. Therefore, a question is SO is 8.76 times (95% confidence interval: 7.8714 — 9.7683, Chi-Square=<.0001) more likely to contain a source code than an initial e-mail in YG. We observe a similar likelihood in answers: While SO contains 2,965 and 4,834 answers with and without source code, YG contains 1,344 and 18,170. This means that an answer in SO is 8.29 times (95% confidence interval: 7.7175 — 8.9099, Chi-Square=<.0001)more likely to contain a source code than an answer in YG.
What are the most common references in discussions?
-
It is common to find links in questions and answers. Interestingly, the presence of links is almost as frequent as source code. In some patterns, the number of links are even higher: Bounded Context *contains links in 164 SO answers (while 113 with source code), *Context Map *contains links in 13 answers (and only 3 with source code), and *Ubiquitous Language (109 against 106). We observe similar patterns also in YG dataset. Interestingly, this happens only in answers; the number of links is never higher than the number of source code in questions.
-
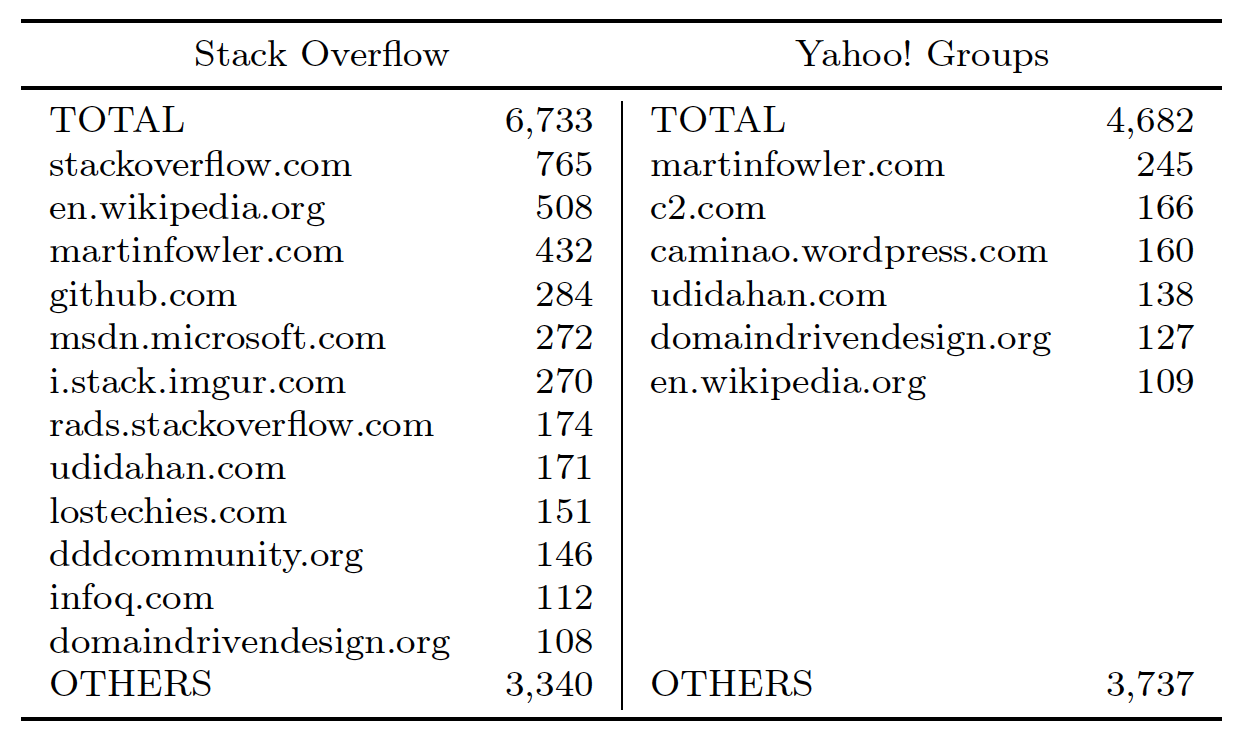
Developers refer to a total of 1,770 different links. SO users cited a total of 956 different links, while YG cited a total of 997. There is an intersection of 183 links between both datasets.
-
StackOverflow and Martin Fowler’s blog are the most popular references. In SO, users often refer to other SO links. In YG, Martin Fowler’s wiki is the most often cited reference. Fowler’s wiki is also popular in SO, with a total of 432 citations. Other common references for both datasets is domaindrivendesign.org (the DDD official website), Wikipedia, and Udi Dahan’s personal blog.
-
Questions and answers in SO are more likely to have links than e-mails in YG. There are 744 and 3,332 questions with and without links in SO. Same numbers for YG are 721 and 4,370. Thus, questions in SO are 1.35 times (95% confidence interval: 1.21 — 1.51, Chi-Square=<.0001) more likely to contain a link than YG. In addition, SO has 2,679 and 5,120 answers with and without links. YG numbers are 2,321 and 17,193. Therefore, answers in SO are 3.87 times (95% confidence interval: 3.63 — 4.13) more likely to contain a link than an answer in YG.
 Common references in DDD posts.
Common references in DDD posts.
Are topics correlated to each other?
We applied the *Apriori algorithm, *the traditional approach to mine association rules. After deciding minimum support and confidence, the algorithm computes the set of all rules that are above these thresholds.
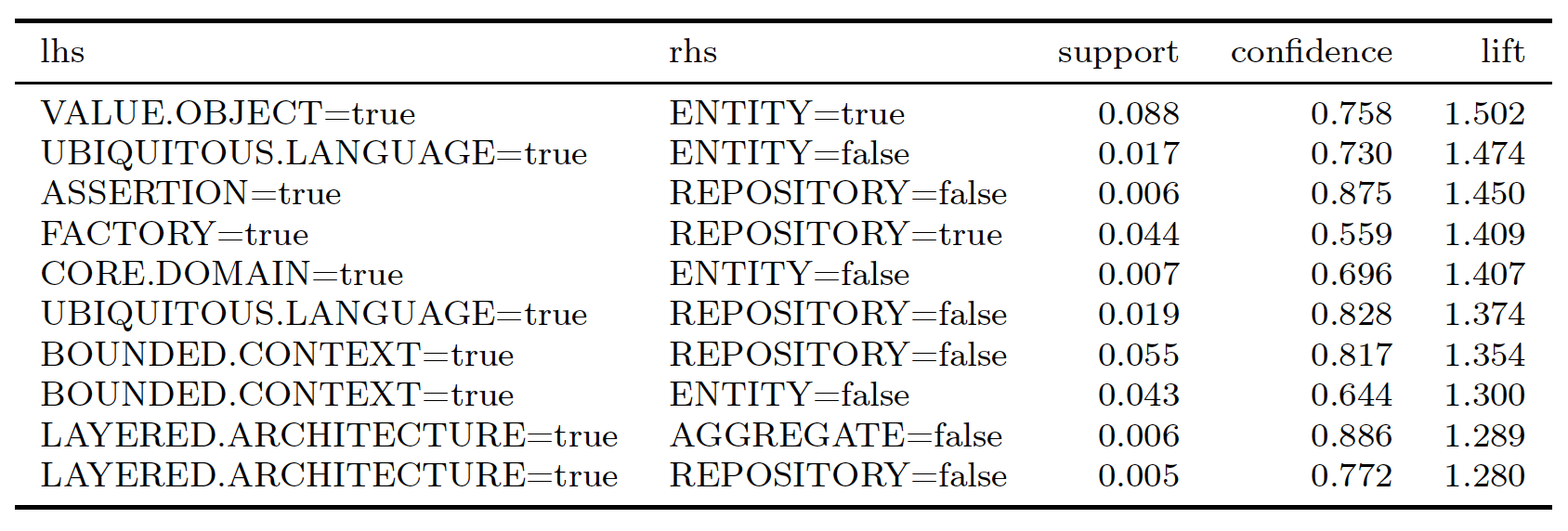
The algorithm was able to generate 2,432 association rules. In the following, we list the top 10 rules ordered by their lift.
 Top 10 association rules for both Stack Overflow and Yahoo! Groups.
Top 10 association rules for both Stack Overflow and Yahoo! Groups.
-
Part II patterns are strongly connected among themselves. The Entity pattern frequently happens with Value Object, Repository, and Aggregate. In addition, Factory is associated with Repository. On the other hand, some of them tend not appear together: Value objects, Aggregates, and Entities are not often found together with Services.
-
Patterns from other parts of the book are disconnected from Part II. Patterns such as Ubiquitous Language, Bounded Context, and Layered Architecture *does not happen together with patterns in Part II. In fact, we observe many rules *A => !B, with A being such patterns, suggesting that they tend to happen alone.
Hopefully, this data shed a light on the important and yet not clear aspects of the practice. Some conclusions based on the findings:
-
Popular DDD patterns in Stack Overflow questions and Yahoo! Groups discussions may be an indication of which patterns require more attention during training and implementation, as they are probably trickier to be implemented in practice. On the other hand, less popular patterns may indicate that either they are not commonly applied (and thus, practitioners do not have questions about them) or that the implementation of such patterns are not straightforward and we should spend more time in clarifying them.
-
It is interesting to see that the Part II of the book is by far the most popular one in both SO and YG. Interestingly, this is the most technical part (as in source code) of the book. Maybe SO and YG are not good mediums to discuss the other topics? Or do developers think that DDD is only about Building Blocks and forget about the entire discussion on strategic design? In the “What I’ve learned about DDD since the book” talk, Evans says that developers give too much attention to the building blocks and less attention to other parts.
-
Although the analysis of type the question was simplistic (keyword matching in the title of the post), the number of “why” questions is lower in both SO and YG when compared to the other keywords. On the other hand, “Why”s are common in books on the topic, such as Evans’ and Vernon’s. Again, an explanation for such a phenomenon could be 1) that SO and YG are not the best place for such discussions, or 2) because the “why”s are already clear to developers, or 3) developers are working on an existing domain model and their questions now focus on how to implement things, rather than understanding why these decisions were taken.
-
We observed several questions about how to apply pattern using a certain technology, e.g., how to make Aggregate Roots to work with NHibernate. Maybe one should spend more time in documenting how to apply DDD in different technologies. The number of how questions may also be a good indicator of this need.
-
In the aforementioned talk, Evans also talks about additions he would do to the book right now, such as Domain Events. Can we find other important additions (or even removals) to DDD in our SO and YG dataset? This is a good future work. Do you wanna help on this? A first start would be to actually read all SO questions and manually classify its content. Maybe with the power of people, we can do it. So, go to this spreadsheet, choose a post (or two), read it, and write what it is about in the spreadsheet!
-
Unsurprisingly, Martin Fowler’s page is a popular reference to link people to well-explained articles on DDD. Interestingly, the number of Github/Gist links is also high, indicating the people commonly share source code and examples. Maybe it’s time for a better link between the book + Fowler’s articles + code examples?
-
The apriori algorithm identified several patterns that tend to not happen with other. A possible explanation for that would be that it is natural to try to isolate the conversation when asking questions as much as possible. However, two of them have strong associations: Entity and Value Objects, and Factory and Repositories. Maybe more material on both topics together would help developers understand their relationship.
I thank Christoph Treude (University of Adelaide), Arie van Deursen (Delft University of Technology), Mario Amaral, Veranildo Veras, Pedro Pessoa, and Mozair Carmo for their insights.